# http://scikit-learn.org/stable/install.html
!sudo pip3 install -U scikit-learn
What is machine learning?¶
Machine learning (ML) is a method of data analysis that automates analytical model building. Using algorithms that iteratively learn from data, ML allows computers to find hidden insights without being explicitly programmed where to look.
The iterative aspect of ML is important because as models are exposed to new data, they are able to independently adapt. They learn from previous computations to produce reliable, repeatable decisions and results. So in general, ML is about learning to do better in the future based on what was experienced in the past.
ML is a core subarea of artificial intelligence and also intersects broadly with other fields, especially statistics, but also mathematics, physics, theoretical computer science and more.
There are many examples of ML problems:
- optical character recognition: categorize images of handwritten characters by the letters represented
- face detection: find faces in images (or indicate if a face is present)
- spam filtering: identify email messages as spam or non-spam
- topic spotting: categorize news articles (say) as to whether they are about politics, ports, entertainment, etc.
- spoken language understanding: within the context of a limited domain, determine the meaning of something uttered by a speaker to the extent that it can be classified into one of a fixed set of categories
- medical diagnosis: diagnose a patient as a sufferer or non-sufferer of some disease
- customer segmentation: predict, for instance, which customers will respond to a particular promotion
- fraud detection: identify credit card transactions (for instance) which may be fraudulent in nature
- weather prediction: predict, for instance, whether or not it will rain tomorrow
What are the two main categories of machine learning?¶
Supervised learning:¶
The data comes with additional attributes (called labels) that we want to predict. This problem can be either:
classification: samples belong to two or more classes and we want to learn from already labeled data how to predict the class of unlabeled data. An example of classification problem would be the handwritten digit recognition example, in which the aim is to assign each input vector to one of a finite number of discrete categories. Another way to think of classification is as a discrete (as opposed to continuous) form of supervised learning where one has a limited number of categories and for each of the n samples provided, one is to try to label them with the correct category or class.
regression: if the desired output consists of one or more continuous variables, then the task is called regression. An example of a regression problem would be the prediction of the length of a salmon as a function of its age and weight.
Unsupervised learning:¶
The training data consists of a set of input vectors without any corresponding target values. The goal in such problems may be to discover groups of similar examples within the data, where it is called clustering, or to determine the distribution of data within the input space, known as density estimation, or to project the data from a high-dimensional space down to two or three dimensions for the purpose of visualization.
How does machine learning "work"?¶

Machine learning with scikit-learn¶
The specific software package we will be using to do ML is called scikit-learn. Scikit-learn is a very powerful package that supports a vast array of ML algorithms (regression, classification, clustering, model selection and dimensionality reduction).
In the current lesson we will consider only supervised ML. Remind, it is broken down into two categories, classification and regression. In classification, the label is discrete, while in regression, the label is continuous. For example, in astronomy, the task of determining whether an object is a star, a galaxy, or a quasar is a classification problem: the label is from three distinct categories (classes). On the other hand, we might wish to estimate the age of an object based on such observations: this would be a regression problem, because the label (age) is a continuous quantity.
scikit-learn comes with several toy datasets that are quite useful for getting an intuition for ML (iris, digits, diabetes etc.). All available datasets may be found here. In this lesson we will consider two datasets - Boston and Iris - and apply regression and classification algorithms to them.
1. Boston dataset (regression)¶
We chose Boston Housing dataset, which contains information about the housing values in suburbs of Boston.
# Import all datasets
from sklearn.datasets import *
# Load Boston Housind data
data_boston = load_boston()
# Get keys of data
data_boston.keys()
# Look at the feature names of boston data set
data_boston.feature_names
# For getting more information about this data we can see the description
print(data_boston.DESCR)
# Look at dataset values
data_boston.data[:2]
The Boston dataset is a dictionary-like object that holds all the data and some metadata about the data. This data is stored in the data key, which is a n_samples x n_features array. In the case of supervised problem like this one, one or more response variables (labels) are stored in the target key.
For better visualization of the features and target examples we use pandas package, that allow to show data as a DataFrame.
import pandas as pd
# Create a DataFrame with the features
boston = pd.DataFrame(data_boston.data, columns=data_boston.feature_names)
# Show a head of the Data Frame
print("Boston dataset contains {} rows.".format(boston.index.size))
boston.head()
Boston's target contains the housing prices. Let's add column with it.
data_boston.target[:10]
# Add column "Price"
boston["PRICE"] = data_boston.target
# Display first 3 rows
boston.head()
Linear regression¶
The predicting the Boston housing prices is a Regression problem. So, we have chosen the LinearRegression provided by scikit-learn.
Linear regression is the oldest and most widely used predictive model in the field of ML. The goal is to minimize the sum of the squared errors to fit a straight line to a set of data points - sum of green distances between blue (train) points and red straight line (line of linear regression) on the picture below (note, we have shown only a few such distances):

You can find further information at Wikipedia.
The linear regression model fits a linear function to a set of data points. The form of the function is:
$$Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + … + \beta_nX_n$$or $$Y = \beta_0 + \sum_{i=1}^{n}\beta_i X_i,$$
where $Y$ is the target variable and $X_1, X_2, ..., X_n$ are the predictor variables and $\beta_1, \beta_2, ..., \beta_n$ are the regression coefficients (also known as weights), $\beta_0$ is constant.
Weights are the solution of the equation system:
$$\sum_{k=1}^{N}\left(Y_k - \beta_0 + \beta_1X_{1k} + \beta_2X_{2k} + … + \beta_nX_{nk}\right)^2 \rightarrow \min$$or $$\frac{\partial}{\partial X_i}\sum_{k=1}^{N}\left(\bar Y_k - \beta_0 + \sum_{i=1}^{n}\beta_i \bar X_{ik}\right)^2 = 0,$$
where $\bar{Y}_k$ and $\bar{X}_{ik}$ are real (train) values of target variable and predictors respectivelly.
First, we will import linear regression from scikit-Learn module and than store this object in a variable lr.
from sklearn.linear_model import LinearRegression
# Create Linear Regression model
lr = LinearRegression()
lr
LinearRegression contains many methods, such as (note, these methods are common for the most of algorithms in scikit-learn):
decision_function(X)- decision function of the linear modelfit(X, y)- fit linear modelget_params()- get parameters for this estimatorpredict(X)- predict using the linear modelscore(X, y)- returns the coefficient of determination R^2 of the prediction
a. Fitting a linear model¶
# Fit Linear Regression
X = data_boston.data
Y = data_boston.target
lr.fit(X, Y)
# Let's look at the intercept and number of coefficients
print("Intercept coefficient:", lr.intercept_)
print("Number of coefficients:", len(lr.coef_))
So, it means, that for each feature we have found one coefficient. Let's see
pd.DataFrame(zip(boston.columns[:-1], lr.coef_), columns = ["features", "coefficients"])
As you can see from the data frame that there is a high correlation between RM (that means average numbers of rooms per dwelling) and prices and NOX (nitric oxides concentration) and prices.
Lets plot a scatter plot between True housing prices and True RM and NOX.
# Import matplotlib library
%matplotlib inline
import matplotlib.pyplot as plt
# Set plot's width and height
plt.rcParams['figure.figsize'] = (18.0, 8.0)
# Plot for RM distribution
plt.subplot(1,2,1)
# Name the axis
plt.xlabel("Average numbers of rooms per dwelling")
plt.ylabel("Prices of Houses")
# Define title
plt.title("Relationship between RM and Price")
# Plot
plt.scatter(boston.RM, boston.PRICE)
# Plot for NOX distribution
plt.subplot(1,2,2)
plt.xlabel("Nitric oxides concentration")
plt.ylabel("Prices of Houses")
plt.title("Relationship between NOX and Price")
plt.scatter(boston.NOX, boston.PRICE, color='g')
plt.show()
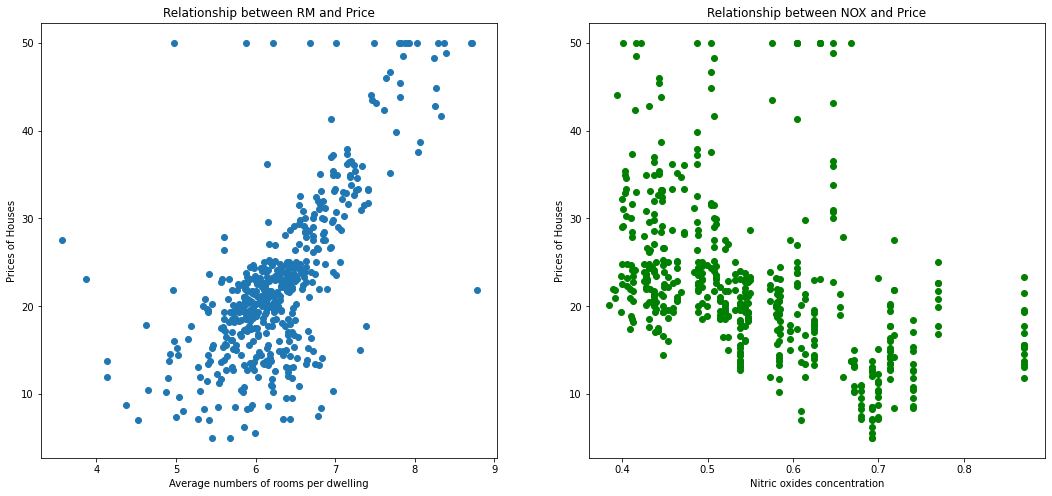
As you can see that there is a positive correlation between RM and housing prices and negative - between NOX and prices.
b. Predicting prices¶
To predict prices we will use lr.predict() function.
# Predict the prices
Y_p = lr.predict(X)
# Print the prices of the first 10 houses
Y_p[:10]
Let's now plot a difference between the right prices and the predicted prices.
plt.xlabel("True prices")
plt.ylabel("Predicted prices")
plt.title("Relationship between true prices and predicted prices")
plt.scatter(Y, Y_p, color='r', label='predicted data', alpha=0.6)
plt.scatter(Y, Y, color='b', label='true data', alpha=0.7)
plt.legend()
plt.show()
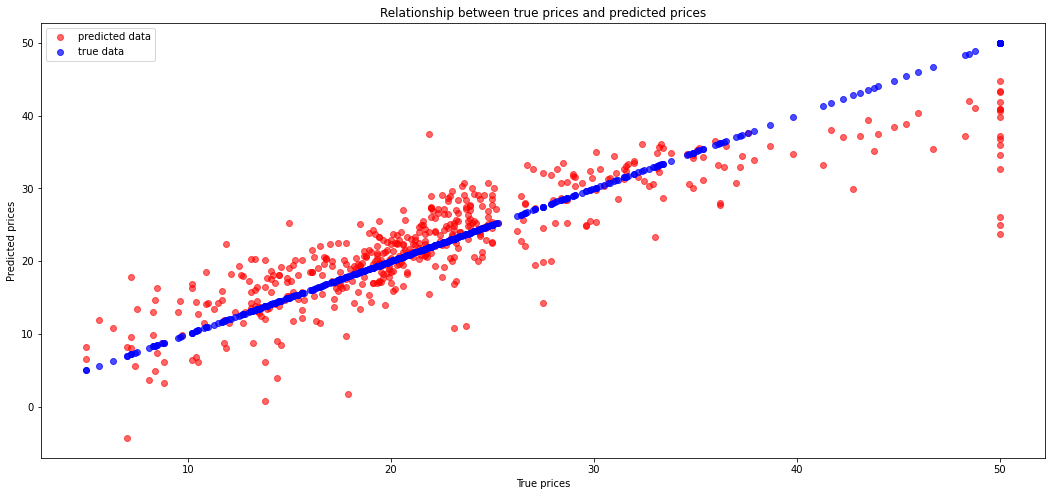
We can see here some errors. Let's calculate the Mean Squared Error.
import numpy as np
# Calculate mse
np.mean((Y - Y_p)**2)
c. Training and test data sets¶
This code will tell us how well the model does on explaining the data we used to fit the model.
In ML, we focus on model performance on unseen data. In order to estimate the performance of the system on unseen data, we can split the data into two sets: the training set and the test set.
The following code will fit a model just using the training data and print out the coefficient of determination for both the training and testing data
# Import function for splitting arrays or matrices into random train and test subsets
from sklearn.model_selection import train_test_split
# Split
X_train, X_test, y_train, y_test = train_test_split(X, Y)
# Show the size of each data
print("X.shape:", X.shape)
print("Y.shape:", Y.shape)
print("X_train.shape:", X_train.shape)
print("X_test.shape:", X_test.shape)
print("y_train.shape:", y_train.shape)
print("y_test.shape:", y_test.shape)
Build a linear regression model using obtained train/test datasets.
# Fit the model
lr_new = LinearRegression()
lr_new.fit(X_train, y_train)
# Get train prediction
pred_train = lr_new.predict(X_train)
# Get test prediction
pred_test = lr_new.predict(X_test)
As in previous paragraph let's calculate mse for train and test prediction
print("Train MSE:", np.mean((y_train - pred_train)**2))
print("Test MSE:", np.mean((y_test - pred_test)**2))
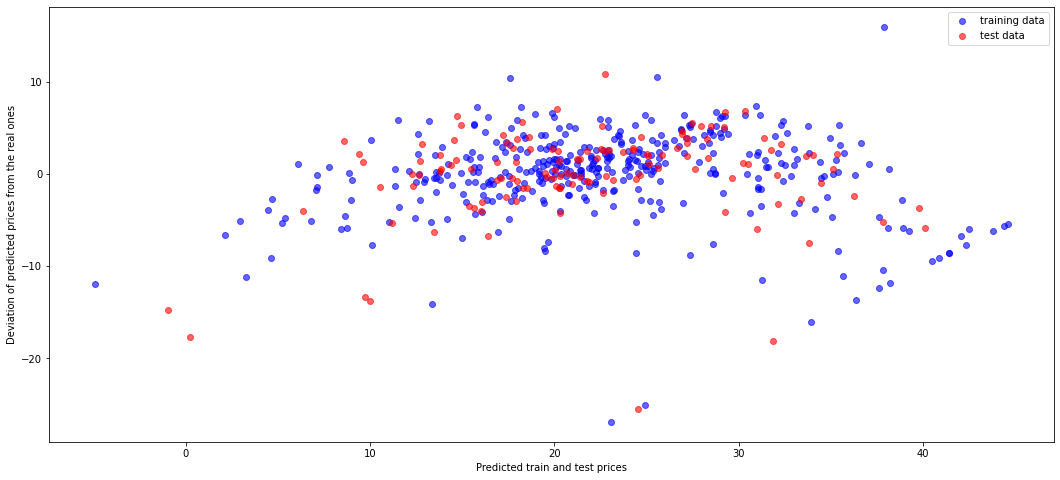
Let's show the residual plot using training (blue) and test (red) data.
plt.xlabel("Predicted train and test prices")
plt.ylabel("Deviation of predicted prices from the real ones")
plt.scatter(pred_train, pred_train-y_train, color = 'b', label="training data", alpha=0.6)
plt.scatter(pred_test, pred_test - y_test, color = 'r', label="test data", alpha=0.6)
plt.legend()
plt.show()
2. Iris dataset (classification)¶
The Iris dataset is a very simple flower database introduced by Ronald Fisher in 1936. It has 150 observations of the iris flower specifying some measurements: sepal length, sepal width, petal length and petal width together with its subtype: Iris setosa, Iris versicolor, Iris virginica. Four features were measured from each sample: the length and the width of the sepals and petals, in centimetres.

Let's display images for each type of iris.
# Load Iris dataset
data_iris = load_iris()
data_iris.keys()
# Information about the content of Iris dataset is also available
print(data_iris.DESCR)
# Let's look at features and target names
data_iris.feature_names
# "target_names"
data_iris.target_names
# Let's look at the data in iris dataset
data_iris.data[:5]
# Let's see target values
data_iris.target
In the Iris dataset we have only three different target values (discrete values 0, 1, 2) unlike to Boston dataset, where target values were distributed continuously. The target value 0 corresponds to Iris Setosa, the number 1 matches with Iris Versicolor and the last number 2 corresponds to Iris Virginica.
# Create a pandas DataFrame for Iris dataset
iris = pd.DataFrame(data=data_iris.data, columns=data_iris.feature_names)
iris["target"] = data_iris.target
print("Iris dataset contains {} rows.".format(iris.index.size))
iris.head()
Build the scatter plot for all width and length values.
from pandas.plotting import scatter_matrix
# set color for each iris kind
color_dict = {0: "blue", # Iris Setosa
1: "red", # Iris Versicolor
2: "green"} # Iris Virginica
colors = iris["target"].map(lambda x: color_dict.get(x))
X = iris.drop('target', axis=1)
Y = iris['target']
ax = scatter_matrix(X, color=colors, alpha=0.8, figsize=(15, 15), diagonal='hist')
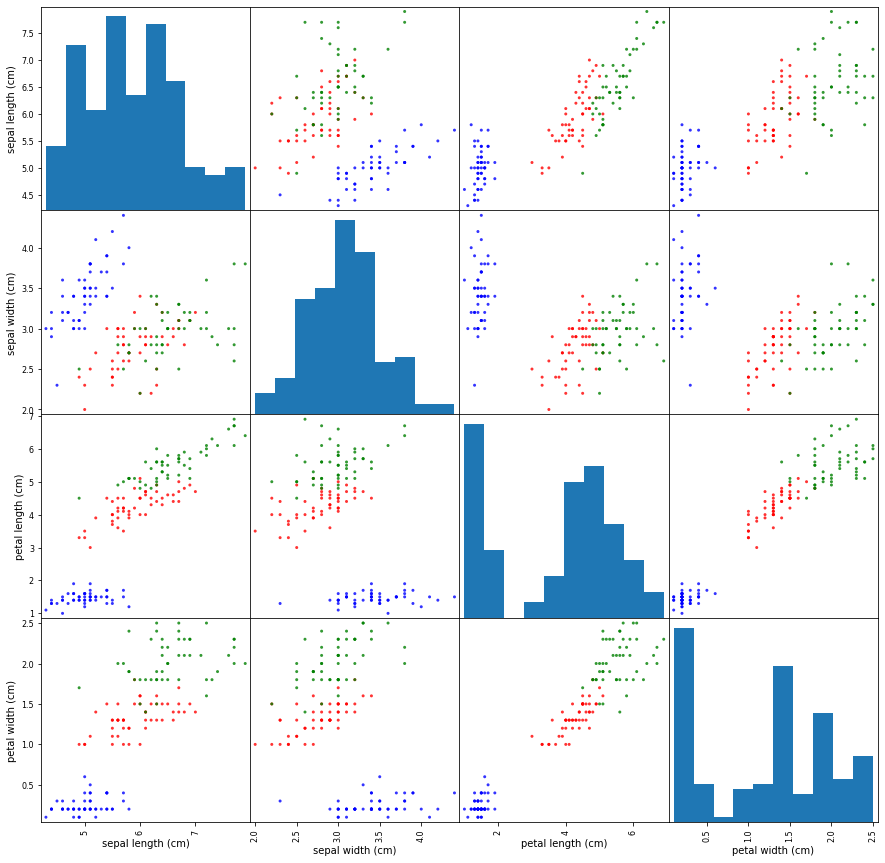
On the set of scatter plot we can see some plots where groups of various kinds of iris can be easily separated with the naked eye, e.g. for pairs (petal length, petal width) or (sepal length, petal lenght). But there some plots with too shuffled points like (sepal width, sepal length), which need more specific approach to separate points to groups.
Support vector machines¶
Iris class prediction is a classification problem.
One of the simplest and common used ML model applied to classification problems is Support Vector Machines (SVM). We chose it for Iris dataset.
SVM is a discriminative classifier formally defined by a separating hyperplane. In other words, given labeled training data (supervised learning), the algorithm outputs an optimal hyperplane which categorizes new examples. Thus, SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall on.
Suppose, we have a linearly separable set of 2D-points which belong to one of two classes (dataset features). In general, we can find the infinite set of separating straight lines. But which of them separates correctly (or with minimal error) these two groups of points? Is any of them better than the others?

In this example we deal with lines and points in the Cartesian plane instead of hyperplanes and vectors in a high dimensional space. This is a simplification of the problem. It is important to understand that this is done only because our intuition is better built from examples that are easy to imagine. However, the same concepts apply to tasks where the examples to classify lie in a space whose dimension is higher than two.
We can intuitively define a criterion to estimate the worth of the lines:
A line is bad if it passes too close to the points because it will be noise sensitive and it will not generalize correctly. Therefore, our goal should be to find the line passing as far as possible from all points.
Then, the operation of the SVM algorithm is based on finding the hyperplane that gives the largest minimum distance to the training examples. Twice, this distance receives the important name of margin within SVM’s theory. Therefore, the optimal separating hyperplane maximizes the margin of the training data.

scikit-learn contains a few various SVM models. We will consider one of them (C-Support Vector Classification - SVC with linear kernel. More details about SVM you can read at Wikipedia and here.
from sklearn.svm import SVC
# Create SVC model
svc = SVC(probability=True, kernel="linear")
svc
# Fir the SVC classifier
svc.fit(X, Y)
Once the model is trained, it can be used to predict the most likely outcome on unseen data. Let's see the length and width of the sepals and petals for each iris kind and write a few new array of these parameters to test chosen sklearn classifiers.
# Draw 4 plots for each feature of all iris kinds
plt.rcParams["figure.figsize"] = (18.0, 4.0)
def draw(col_num):
print(X.columns[col_num])
x = np.arange(50)
y1 = X.loc[:49, X.columns[col_num]].values # Iris Setosa
y2 = X.loc[50:99, X.columns[col_num]].values # Iris Versicolor
y3 = X.loc[100:149, X.columns[col_num]].values # Iris Virginica
plt.plot(x, y1, 'bo--')
plt.plot(x, y2, 'rD--')
plt.plot(x, y3, 'gv--')
# Linear trendlines
p1 = np.poly1d(np.polyfit(x, y1, 1))
p2 = np.poly1d(np.polyfit(x, y2, 1))
p3 = np.poly1d(np.polyfit(x, y3, 1))
plt.plot(x, p1(x), 'b-')
plt.plot(x, p2(x), 'r-')
plt.plot(x, p3(x), 'g-')
plt.show()
for i in range(4):
draw(i)
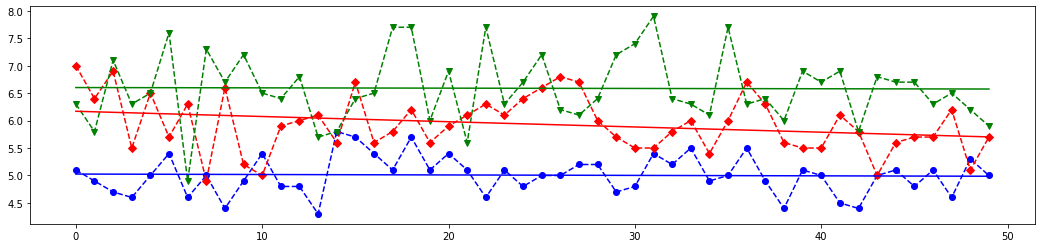
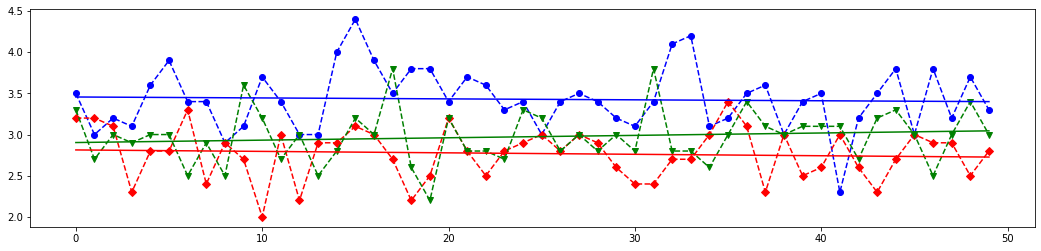
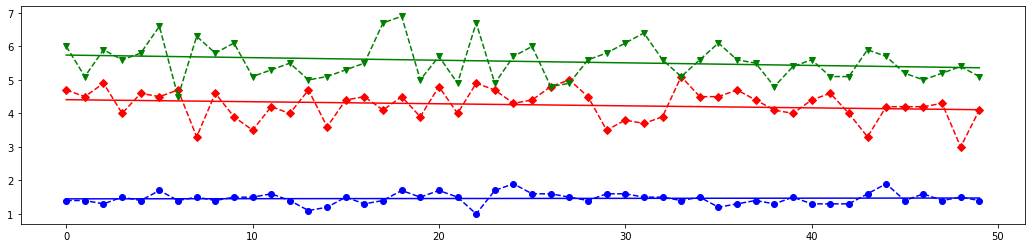
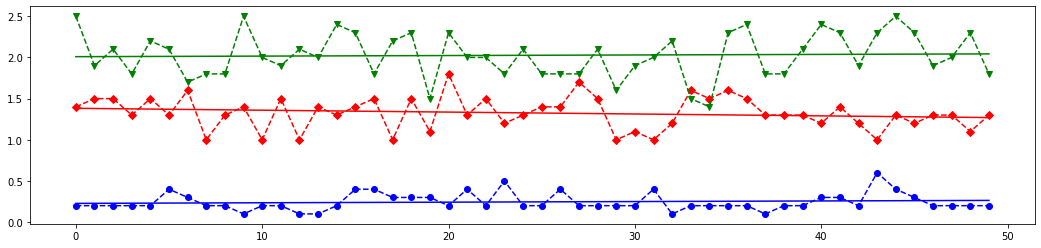
# Based on above plots let's create an array with features values close to each iris kind
# and with one value with is far from each class
X_new = [
[5.0, 3.6, 1.3, 0.25], # very similar to the Iris Setosa
[7.0, 3.0, 5.0, 1.5], # very similar to the Iris Versicolor
[6.5, 3.0, 6.2, 2.25], # very similar to the Iris Virginica
[3.0, 1.5, 2.5, 1.0] # length and width parameters are far from each group
]
# The last element of `X_new` is most closest above blue (class 0) line on the first plot from the above set,
# it is almost between red (class 1) and blue line on the second plot,
# but it is most closest to the red line on the third and fourth lines.
# Meaning, this features set should corresponds to class 1.
# Let's see which result the SVM classifier will give.
predicted = svc.predict(X_new)
# Let's look at how scikit-learn classified above four arrays. Do you remember that
# 0 corresponds to Iris Setosa
# 1 is Iris Versicolor
# 2 coincides with Iris Virginica
print(predicted)
#SVM Classifier have builded function `score()`, which returns the mean accuracy on the given test data and labels.
svc.score(X, Y)
As you can see the results of prediction are those we discussed above. Nice work, SVM classifier!
Confusion matrix:¶
Let's build a confusion matrix which is a specific table layout that allows visualization of the performance of an algorithm.
Each column of the matrix represents the instances in a predicted class while each row represents the instances in an actual class (or vice-versa). The diagonal elements represent the number of points for which the predicted label is equal to the true label, while off-diagonal elements are those that are mislabeled by the classifier. The higher the diagonal values of the confusion matrix the better, indicating many correct predictions.
from sklearn.metrics import confusion_matrix
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
y_pred = svc.fit(X_train, y_train).predict(X_test)
# Compute confusion matrix
cm = confusion_matrix(y_test, y_pred)
np.set_printoptions(precision=2)
print('Confusion matrix')
print(cm)
plt.rcParams['figure.figsize'] = (6.0, 6.0)
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion matrix')
plt.colorbar()
tick_marks = np.arange(len(data_iris.target_names))
plt.xticks(tick_marks, data_iris.target_names, rotation=45)
plt.yticks(tick_marks, data_iris.target_names)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()

Function accuracy_score of sklearn.metrics module allows to know how often the classifier was correct.
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_pred))
ROC Curves and Area Under the Curve (AUC):¶
Wouldn't it be nice if we could see how sensitivity and specificity are affected by various thresholds, without actually changing the threshold? Sure, the ROC helps us with this.
ROC (Receiver Operating Characteristic) curves typically feature true positive rate on the Y axis, and false positive rate on the X axis. This means that the top left corner of the plot is the “ideal” point - a false positive rate of zero, and a true positive rate of one. This is not very realistic, but it does mean that a larger area under the curve (AUC) is usually better.
ROC curves are typically used in binary classification to study the output of a classifier. In order to extend ROC curve and ROC area to multi-class or multi-label classification, it is necessary to binarize the output. One ROC curve can be drawn per label, but one can also draw a ROC curve by considering each element of the label indicator matrix as a binary prediction (micro-averaging).
ROC curve can help you to choose a threshold that balances sensitivity and specificity in a way that makes sense for your particular context. You can't actually see the thresholds used to generate the curve on the ROC curve itself.
More info you can find on Wikipedia and here.
AUC is the percentage of the ROC plot that is underneath the curve. AUC is useful as a single number summary of classifier performance.
If you randomly chose one positive and one negative observation, AUC represents the likelihood that your classifier will assign a higher predicted probability to the positive observation.
AUC is useful even when there is high class imbalance (unlike classification accuracy).
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
# We can also use directly loaded iris dataset, which contains numpy arrays
X = data_iris.data
Y = data_iris.target
# Binarize the targets
y_bin = label_binarize(Y, classes=[0, 1, 2])
print("Binarized targets:")
print(y_bin[:3])
print("...\n", y_bin[50:53])
print("...\n", y_bin[100:103], "\n...")
n_classes = y_bin.shape[1]
n_classes
# shuffle and split equals training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y_bin, test_size=.5)
# Now we have three various labels.
# OneVsRestClassifier consists in fitting one classifier per class.
# For each classifier, the class is fitted against all the other classes.
# This is the most commonly used strategy for multiclass classification and is a fair default choice.
svc_roc = OneVsRestClassifier(SVC(kernel='linear', probability=True))
# Learn to predict each class against the other
y_score = svc_roc.fit(X_train, y_train).decision_function(X_test)
from sklearn.metrics import roc_curve, auc
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
thresholds = dict()
roc_auc = dict()
roc_auc_scores = dict()
for i in range(n_classes):
fpr[i], tpr[i], thresholds[i] = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], thresholds["micro"] = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
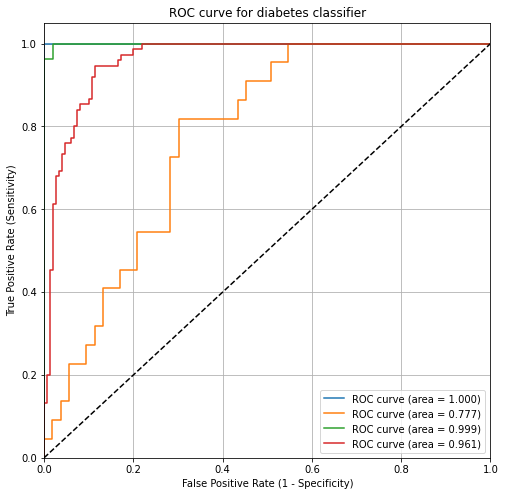
print("roc_auc:")
for key, val in roc_auc.items():
try:
print("for {} is {}".format(data_iris.target_names[key], val))
except:
print("for micro is {}".format(val))
# Plot of a ROC curve for a specific class
plt.rcParams['figure.figsize'] = (8.0, 8.0)
plt.figure()
plt.plot(fpr[0], tpr[0], label='ROC curve (area = %0.3f)' % roc_auc[0])
plt.plot(fpr[1], tpr[1], label='ROC curve (area = %0.3f)' % roc_auc[1])
plt.plot(fpr[2], tpr[2], label='ROC curve (area = %0.3f)' % roc_auc[2])
plt.plot(fpr["micro"], tpr["micro"], label='ROC curve (area = %0.3f)' % roc_auc["micro"])
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.title('ROC curve for diabetes classifier')
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('True Positive Rate (Sensitivity)')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()
Confusion matrix advantages:
- Allows you to calculate a variety of metrics.
- Useful for multi-class problems (more than two response classes).
ROC/AUC advantages:
- Does not require you to set a classification threshold.
- Still useful when there is high class imbalance.
Exersice:¶
In this task you need to build a model to classify images of handwritten digits, which are provided in scikit-learn datasets. To load the digits and display 18 of the examplars you may use the following code:
from sklearn.datasets import load_digits
import numpy as np
digits = load_digits()
fig = plt.figure()
fig.subplots_adjust(hspace=-0.5, wspace=0.2)
for i in range(18):
subplot = fig.add_subplot(3,6,i+1)
subplot.imshow(digits.images[i], cmap=plt.cm.binary, interpolation='nearest')
# label the image with the target value
subplot.text(0, 7, str(digits.target[i]), size=20)
plt.show()
1) Investigate all digits datasets keyses and look at how handwritten digits are represented there.
2) Create a new linear
SVCclassifier. Select one item from digits dataset (one digit) in random way - this is the digit which you need to classify. Fit the classifier with all digits with the exception of the previously selected digit (Xarray) and respective targets (Yarray). Predict the label of the selected digit and draw it as shown on example above. Check whether predicted label and the picture coincide.3) Use
train_test_splitfunction do divide whole dataset into train and test parts. Note, test part should contain 30% of items from whole dataset, then the train part will consist from 70% of digits. Build logistic regression model (Despite its name it is a classification algorithm, which is common used at images recognition/detection) anf fit it based on obtained train and test data. Calculate an display the accuracy of training and testing for the model.4) For the train and test data build a linear VC classifier. Construct to both of them the confusion matrix and calucate the
accuracy_scorevalue. Also draw ROC curves for each class from dataset (each digit) and calculate the AUC value for them.
