shameless self-promotion
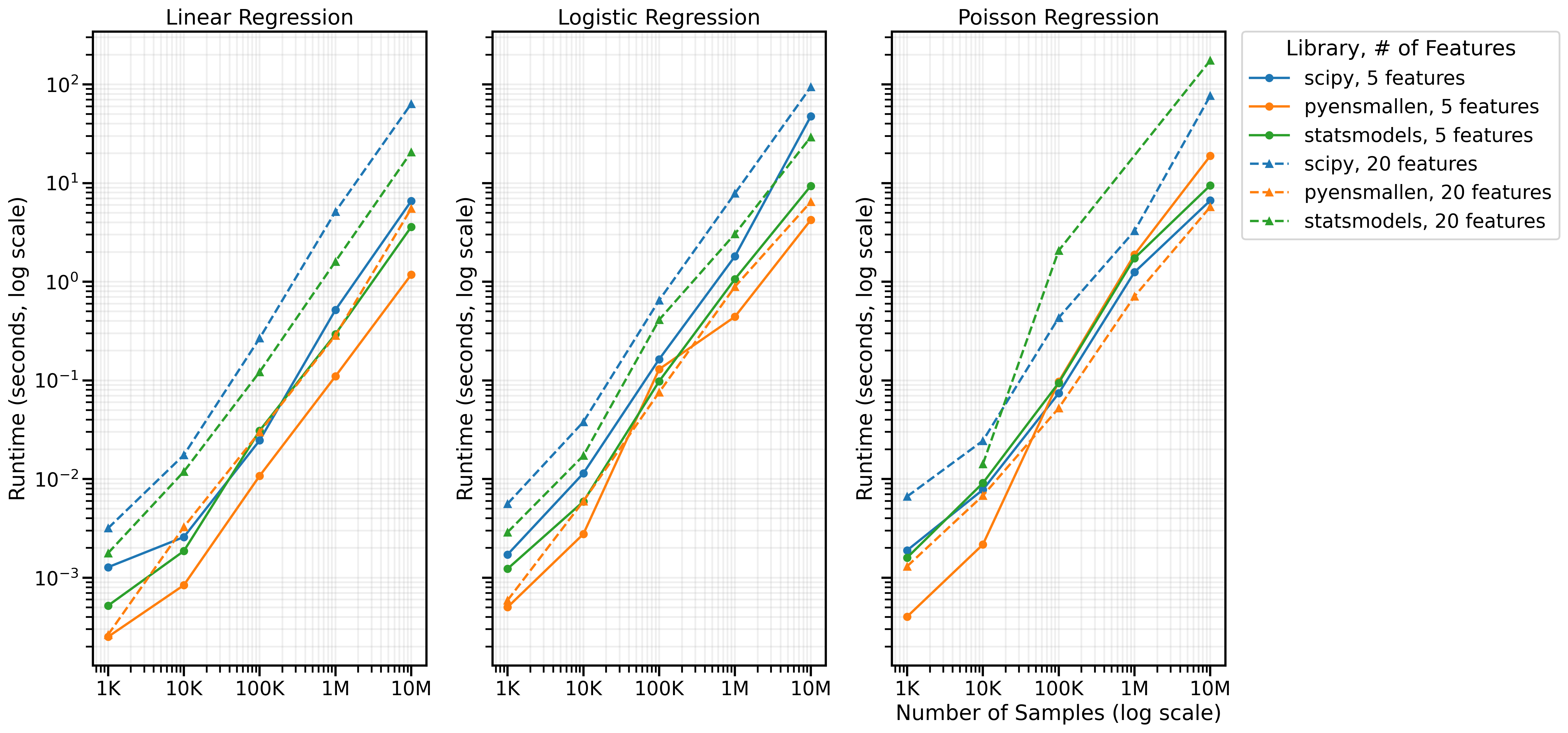
- pyensmallen got a fresh coat of paint, refactor, and performance benchmarks. It is very, very fast; use it wherever you’d use
scipy.optimizeand more. It powers the optimization insynthlearnersand will soon also power a fast implementation of GMM ingmm. Will hopefully be presenting this at a few conferences soon.
- webassembly-based python anywhere. Forked a fascinating jupyterlite project to have a functional jupyter notebook running the basic scientific python stack on my phone. Become a parody of yourself.
links
-
Liu et al teaches social choice and game theory to LLM-focussed researchers. The paper starts from basics of Condorcet cycles and the resultant impossibility of representing human preferences in RLHF-like techniques, adapts Arrow’s theorem for LLMs (Theorem 2.1, “Necessary and Sufficient Conditions for Reward Modeling”), and an summarises alternative approach called Nash Learning from Human Feedback (NLHF), which sets up preference modelling is a game involving two models. Clearly written intro to social choice for LLM researchers; would be great if LLM-ers slowed down enough to carefully work through this paper instead of yelling “moar parameters”.
- Related: Competence estimation models following from Dawid-Skene 1979 are a useful aggregation method when human annotations come from a mix of varying levels of expertise. The same can apply to aggregating LLM labels in LLM judge settings.
- Related: The LLM alignment from an experimental point of view paper linked in 2025-03-01 edition
-
Stewart, Bach, Berthet on the surprising effectiveness of reformulating regression as a classification task in training neural networks, i.e. an encoder-decoder setup for regression. The authors cover a setting with (1) a target encoder model, which bins the support of the real-valued response, (2) a classification model that fits a softmax to predict the bin, and (3) a decoder model which is used to predict the response by projecting the logits back into the response space. The authors extend this setup to a ‘soft-binning’ setting where the response for classification is now around centers instead of dummy variables indicating bin membership.
-
Baker et al a gigantic modern difference-in-differences review paper. Starts with the basic 2-period setting with means, then regression, incorporating covariates, multiple time periods and staggered adoption.
-
Zhang, Lee, Dobriban on statistical inference via randomized algorithms. In many ‘big data’ settings, we cannot operate directly on the original dataset due to its size, and so we must sample it in a specific way to make estimating statistical parameters computationally feasible. This sampling procedure mimics the thought experiment in classical statistics wherein we draw from a superpopulation, and under certain conditions, the sampling procedure can be used to perform inference (i.e. construct confidence intervals, not construct fitted values, Jensen Huang be damned).
-
fd is an excellent alternative to the
findcommand. Pairs well withfzfandnnn. -
Noclip’s series on Dwarf Fortress is characteristically excellent. I never had the patience to persevere through DF’s general oddities, but it is a fascinating piece of software and the community around it is an endless source of entertainment.
-
Tigran Hamasyan played an incredible gig at SFJAZZ on the 21st March. He’s a genius and his band (including Matt Gartska from Animals as Leaders) played a hell of a show.