links
papers
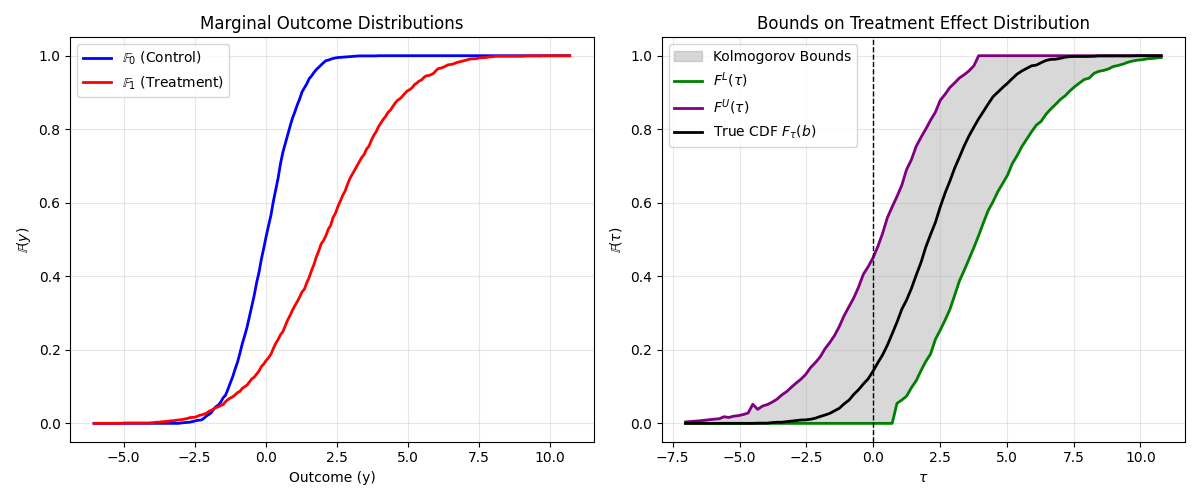
- Frank DiTraglia’s Causal Inference Notes is excellent and self-contained. I particularly like the partial-identification chapter, which is (unfortunately) somewhat rare among causal inference texts. It inspired me to work through the implementation of the Kolmogorov bounds for assumption-free bounds on the individual treatment effects based on the marginal distributions of observed outcomes later in the post.
- Ben-Michael on partial identification via linear programming, which neatly nests several standard partially identified parameters and proposes a clearcut way to incorporate covariates
- Simchi-Levi and Wang ( PMLR version ) on experimental design for pricing experiments, which are essential to estimate elasticities but have real dollar values associated with them (and tail risks of huge losses).
- Gao and Ding proposes regression adjustments (think network analogues of Lin(2013) fully interacted regression / regression imputation) and provides a characteristically excellent exposition of central issues in the interference setting along the way.
code, music
- fwb for the fractional weighted bootstrap (bayesian bootstrap) in R
- Pranjal Rawat’s repository of python tools for econometrics is fairly comprehensive (and features a few packages developed by yours truly).
- Delicatessen is an excellent package for m-estimation in python. It really commits to the bit with the sandwich imagery too.
- King Gizzard’s Phantom Island is great and rewards repeated listens. They are creatively restless as usual and they’ve landed on a really interesting orchestral sound. This is their 27th(!!!) album in 14 years.
- Ando San’s EP is excellent. There are very few guitarist-rappers around (lil wayne doesn’t count) and thump riffs make for excellent backbeats.
self-promotion
- A recording of our webinar on open source econometrics in python is on youtube , (slides ). I’m fond of the swiss-army-knife vs screwdriver analogy for API design + scope control - feel free to email me to vehemently disagree.
- pushed some updates to my
cbpyscovariate balancing propensity score package that implements entropy balancing (and more generally automatic estimation of riesz representers) in pytorch. There’s a close-to-done PR that implements the three forms of L2 balancing weights from Bruns-Smith et al vibe-coded with Jules, an impressive and hyper-active agentic programmer built on top of gemini - we just merged (Alex did all the work and I spectated) a Quantile Regression implementation into pyfixest. In the process, I spent a couple of hours reading up on solution techniques for the non-standard numerical problem that pinball loss poses. Some reference implementations and benchmarks here; the fastest (interior point, frisch-newton) method is implemented in pyfixest.
- a python script and demo to call local LLMs via
ollamaand export their output to markdown with Derek Willis’ Iguana naming problem - funny how all LLMs converge on tedious twee-ness when going for ‘creative/unique’ candidates.
kolmogorov bounds for ITEs
Per Fan and Park (2010), one can use Kolmogorov’s bounds on differences of random variables to bound the individual treatment effect CDF without any additional assumptions.
Lower-bound
Upper-bound
#
def FL(b, y1, y0):
"""
Compute F^L(b) - lower bound of Kolmogorov bounds.
"""
def f(x):
# Note the negative sign as we are maximizing
return -(np.mean(y1 < x) - np.mean(y0 < x - b))
# Optimize over the range of observed outcomes
bounds = (min(np.min(y1), np.min(y0)), max(np.max(y1), np.max(y0)))
result = minimize_scalar(f, bounds=bounds, method="bounded")
return max(-result.fun, 0)
def FU(b, y1, y0):
"""
Compute F^U(b) - upper bound of Kolmogorov bounds.
"""
def f(x):
return np.mean(y1 < x) - np.mean(y0 < x - b)
# Optimize over the range of observed outcomes
bounds = (min(np.min(y1), np.min(y0)), max(np.max(y1), np.max(y0)))
result = minimize_scalar(f, bounds=bounds, method="bounded")
return 1 + min(result.fun, 0)
#
# Example: Simulate data and compute bounds
np.random.seed(42)
# Generate sample data with known individual treatment effects
N = 2000
a = 0
b_true = np.random.normal(2, 2, size=N) # True individual treatment effects
u = np.random.normal(0, 1, size=N)
Y = np.c_[a + u, a + b_true + u]
y0, y1 = Y[:, 0], Y[:, 1]
# Verify: individual treatment effects
true_effects = y1 - y0 # Should equal b_true exactly
print(f"True effects equal b_true: {np.allclose(true_effects, b_true)}")
# Set up grid for bounds computation
K = 100
min_diff, max_diff = y1.min() - y0.min(), y1.max() - y0.max()
b_grid = np.linspace(min_diff - 5, max_diff + 5, K)
#
ffmpeg+whisper-cli for easy local transcription
Whisper is an underrated foundation model that OpenAI built and released well before going viral with ChatGPT but a similarly ground-breaking example of Sutton’s bitter lesson. GGerganov wrote it in performant (and versatile - he’s gotten it to run on phones!) C++.
- first install whisper.cpp on your system. This may require building from scratch. Download the right sized model for your needs.
- put this in a bash script called
converter.sh; it takes an arbitrary audio input file and converts it into a wav file with the right sample rate for the whisper model. apply it to bulk-convert a directory of mp3s.
convert_audio() {
local input_file="$1"
local output_file="$2"
local sample_rate="${3:-16000}" # Default sample rate is 16000 Hz
local channels="${4:-1}" # Default number of channels is 1 (mono)
local audio_codec="${5:-pcm_s16le}" # Default audio codec is pcm_s16le
# Check if input file exists
if [[ ! -f "$input_file" ]]; then
echo "Error: Input file '$input_file' not found!"
return 1
fi
# Run ffmpeg command
ffmpeg -i "$input_file" -ar "$sample_rate" -ac "$channels" -c:a "$audio_codec" "$output_file"
# Check if the conversion was successful
if [[ $? -eq 0 ]]; then
echo "Conversion successful: $output_file"
else
echo "Error: Conversion failed!"
return 1
fi
}- store
./build/bin/whisper-cli -m models/ggml-base.en.bin -f $1`
in a new bash script called runner.sh. This calls the whisper-cli executable with the model binary input on an input $1.
- bulk transcribe in a loop
for f in ~/Downloads/interviews/*.wav; do ./runnerl.sh $f | tee ${f%%.*}_transcribed.md ; done- Optional:
arecord -f S16_LE -c1 -r16000 path_to_record.wavrecords to path_to_record.wav and whisper can act on it immediately, so I just need to figure out how to cut out the middleman (writing wav to disk) and pipe to whisper directly, and one could build real-time transcriptions for fully local note-taking via speech-to-text. For example, I just ran arecord to make this and whisper generated
[00:00:00.000 --> 00:00:05.000] The quick brown fox jumped over the lazy dog.