Numpy - multidimensional data arrays¶
J.R. Johansson (jrjohansson at gmail.com)
The latest version of this IPython notebook lecture is available at http://github.com/jrjohansson/scientific-python-lectures.
The other notebooks in this lecture series are indexed at http://jrjohansson.github.io.
# what is this line all about?!? Answer in lecture 4
%matplotlib inline
import matplotlib.pyplot as plt
Introduction¶
The numpy package (module) is used in almost all numerical computation using Python. It is a package that provide high-performance vector, matrix and higher-dimensional data structures for Python. It is implemented in C and Fortran so when calculations are vectorized (formulated with vectors and matrices), performance is very good.
To use numpy you need to import the module, using for example:
from numpy import *
In the numpy package the terminology used for vectors, matrices and higher-dimensional data sets is array.
Creating numpy arrays¶
There are a number of ways to initialize new numpy arrays, for example from
- a Python list or tuples
- using functions that are dedicated to generating numpy arrays, such as
arange,linspace, etc. - reading data from files
From lists¶
For example, to create new vector and matrix arrays from Python lists we can use the numpy.array function.
# a vector: the argument to the array function is a Python list
v = array([1,2,3,4])
v
# a matrix: the argument to the array function is a nested Python list
M = array([[1, 2], [3, 4]])
M
The v and M objects are both of the type ndarray that the numpy module provides.
type(v), type(M)
The difference between the v and M arrays is only their shapes. We can get information about the shape of an array by using the ndarray.shape property.
v.shape
M.shape
The number of elements in the array is available through the ndarray.size property:
M.size
Equivalently, we could use the function numpy.shape and numpy.size
shape(M)
size(M)
So far the numpy.ndarray looks awefully much like a Python list (or nested list). Why not simply use Python lists for computations instead of creating a new array type?
There are several reasons:
- Python lists are very general. They can contain any kind of object. They are dynamically typed. They do not support mathematical functions such as matrix and dot multiplications, etc. Implementing such functions for Python lists would not be very efficient because of the dynamic typing.
- Numpy arrays are statically typed and homogeneous. The type of the elements is determined when the array is created.
- Numpy arrays are memory efficient.
- Because of the static typing, fast implementation of mathematical functions such as multiplication and addition of
numpyarrays can be implemented in a compiled language (C and Fortran is used).
Using the dtype (data type) property of an ndarray, we can see what type the data of an array has:
M.dtype
We get an error if we try to assign a value of the wrong type to an element in a numpy array:
M[0,0] = "hello"
If we want, we can explicitly define the type of the array data when we create it, using the dtype keyword argument:
M = array([[1, 2], [3, 4]], dtype=complex)
M
Common data types that can be used with dtype are: int, float, complex, bool, object, etc.
We can also explicitly define the bit size of the data types, for example: int64, int16, float128, complex128.
Using array-generating functions¶
For larger arrays it is inpractical to initialize the data manually, using explicit python lists. Instead we can use one of the many functions in numpy that generate arrays of different forms. Some of the more common are:
arange¶
# create a range
x = arange(0, 10, 1) # arguments: start, stop, step
x
x = arange(-1, 1, 0.1)
x
linspace and logspace¶
# using linspace, both end points ARE included
linspace(0, 10, 25)
logspace(0, 10, 10, base=e)
mgrid¶
x, y = mgrid[0:5, 0:5] # similar to meshgrid in MATLAB
x
y
random data¶
from numpy import random
# uniform random numbers in [0,1]
random.rand(5,5)
# standard normal distributed random numbers
random.randn(5,5)
diag¶
# a diagonal matrix
diag([1,2,3])
# diagonal with offset from the main diagonal
diag([1,2,3], k=1)
zeros and ones¶
zeros((3,3))
ones((3,3))
File I/O¶
Comma-separated values (CSV)¶
A very common file format for data files is comma-separated values (CSV), or related formats such as TSV (tab-separated values). To read data from such files into Numpy arrays we can use the numpy.genfromtxt function. For example,
!head stockholm_td_adj.dat
data = genfromtxt('stockholm_td_adj.dat')
data.shape
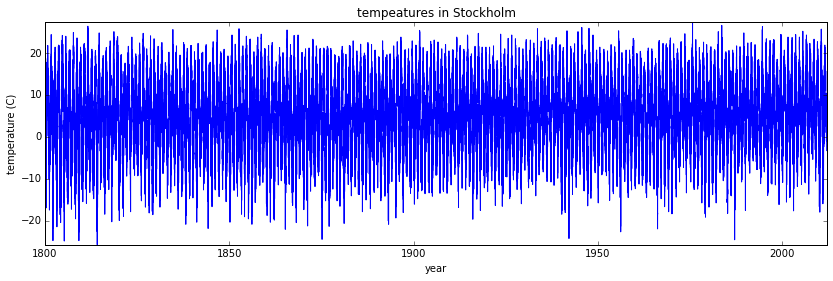
fig, ax = plt.subplots(figsize=(14,4))
ax.plot(data[:,0]+data[:,1]/12.0+data[:,2]/365, data[:,5])
ax.axis('tight')
ax.set_title('tempeatures in Stockholm')
ax.set_xlabel('year')
ax.set_ylabel('temperature (C)');
Using numpy.savetxt we can store a Numpy array to a file in CSV format:
M = random.rand(3,3)
M
savetxt("random-matrix.csv", M)
!cat random-matrix.csv
savetxt("random-matrix.csv", M, fmt='%.5f') # fmt specifies the format
!cat random-matrix.csv
Numpy's native file format¶
Useful when storing and reading back numpy array data. Use the functions numpy.save and numpy.load:
save("random-matrix.npy", M)
!file random-matrix.npy
load("random-matrix.npy")
More properties of the numpy arrays¶
M.itemsize # bytes per element
M.nbytes # number of bytes
M.ndim # number of dimensions
Manipulating arrays¶
Indexing¶
We can index elements in an array using square brackets and indices:
# v is a vector, and has only one dimension, taking one index
v[0]
# M is a matrix, or a 2 dimensional array, taking two indices
M[1,1]
If we omit an index of a multidimensional array it returns the whole row (or, in general, a N-1 dimensional array)
M
M[1]
The same thing can be achieved with using : instead of an index:
M[1,:] # row 1
M[:,1] # column 1
We can assign new values to elements in an array using indexing:
M[0,0] = 1
M
# also works for rows and columns
M[1,:] = 0
M[:,2] = -1
M
Index slicing¶
Index slicing is the technical name for the syntax M[lower:upper:step] to extract part of an array:
A = array([1,2,3,4,5])
A
A[1:3]
Array slices are mutable: if they are assigned a new value the original array from which the slice was extracted is modified:
A[1:3] = [-2,-3]
A
We can omit any of the three parameters in M[lower:upper:step]:
A[::] # lower, upper, step all take the default values
A[::2] # step is 2, lower and upper defaults to the beginning and end of the array
A[:3] # first three elements
A[3:] # elements from index 3
Negative indices counts from the end of the array (positive index from the begining):
A = array([1,2,3,4,5])
A[-1] # the last element in the array
A[-3:] # the last three elements
Index slicing works exactly the same way for multidimensional arrays:
A = array([[n+m*10 for n in range(5)] for m in range(5)])
A
# a block from the original array
A[1:4, 1:4]
# strides
A[::2, ::2]
Fancy indexing¶
Fancy indexing is the name for when an array or list is used in-place of an index:
row_indices = [1, 2, 3]
A[row_indices]
col_indices = [1, 2, -1] # remember, index -1 means the last element
A[row_indices, col_indices]
We can also use index masks: If the index mask is an Numpy array of data type bool, then an element is selected (True) or not (False) depending on the value of the index mask at the position of each element:
B = array([n for n in range(5)])
B
row_mask = array([True, False, True, False, False])
B[row_mask]
# same thing
row_mask = array([1,0,1,0,0], dtype=bool)
B[row_mask]
This feature is very useful to conditionally select elements from an array, using for example comparison operators:
x = arange(0, 10, 0.5)
x
mask = (5 < x) * (x < 7.5)
mask
x[mask]
Functions for extracting data from arrays and creating arrays¶
where¶
The index mask can be converted to position index using the where function
indices = where(mask)
indices
x[indices] # this indexing is equivalent to the fancy indexing x[mask]
diag¶
With the diag function we can also extract the diagonal and subdiagonals of an array:
diag(A)
diag(A, -1)
take¶
The take function is similar to fancy indexing described above:
v2 = arange(-3,3)
v2
row_indices = [1, 3, 5]
v2[row_indices] # fancy indexing
v2.take(row_indices)
But take also works on lists and other objects:
take([-3, -2, -1, 0, 1, 2], row_indices)
choose¶
Constructs an array by picking elements from several arrays:
which = [1, 0, 1, 0]
choices = [[-2,-2,-2,-2], [5,5,5,5]]
choose(which, choices)
Linear algebra¶
Vectorizing code is the key to writing efficient numerical calculation with Python/Numpy. That means that as much as possible of a program should be formulated in terms of matrix and vector operations, like matrix-matrix multiplication.
Scalar-array operations¶
We can use the usual arithmetic operators to multiply, add, subtract, and divide arrays with scalar numbers.
v1 = arange(0, 5)
v1 * 2
v1 + 2
A * 2, A + 2
Element-wise array-array operations¶
When we add, subtract, multiply and divide arrays with each other, the default behaviour is element-wise operations:
A * A # element-wise multiplication
v1 * v1
If we multiply arrays with compatible shapes, we get an element-wise multiplication of each row:
A.shape, v1.shape
A * v1
Matrix algebra¶
What about matrix mutiplication? There are two ways. We can either use the dot function, which applies a matrix-matrix, matrix-vector, or inner vector multiplication to its two arguments:
dot(A, A)
dot(A, v1)
dot(v1, v1)
Alternatively, we can cast the array objects to the type matrix. This changes the behavior of the standard arithmetic operators +, -, * to use matrix algebra.
M = matrix(A)
v = matrix(v1).T # make it a column vector
v
M * M
M * v
# inner product
v.T * v
# with matrix objects, standard matrix algebra applies
v + M*v
If we try to add, subtract or multiply objects with incomplatible shapes we get an error:
v = matrix([1,2,3,4,5,6]).T
shape(M), shape(v)
M * v
See also the related functions: inner, outer, cross, kron, tensordot. Try for example help(kron).
Array/Matrix transformations¶
Above we have used the .T to transpose the matrix object v. We could also have used the transpose function to accomplish the same thing.
Other mathematical functions that transform matrix objects are:
C = matrix([[1j, 2j], [3j, 4j]])
C
conjugate(C)
Hermitian conjugate: transpose + conjugate
C.H
We can extract the real and imaginary parts of complex-valued arrays using real and imag:
real(C) # same as: C.real
imag(C) # same as: C.imag
Or the complex argument and absolute value
angle(C+1) # heads up MATLAB Users, angle is used instead of arg
abs(C)
Matrix computations¶
Inverse¶
linalg.inv(C) # equivalent to C.I
C.I * C
Determinant¶
linalg.det(C)
linalg.det(C.I)
Data processing¶
Often it is useful to store datasets in Numpy arrays. Numpy provides a number of functions to calculate statistics of datasets in arrays.
For example, let's calculate some properties from the Stockholm temperature dataset used above.
# reminder, the tempeature dataset is stored in the data variable:
shape(data)
mean¶
# the temperature data is in column 3
mean(data[:,3])
The daily mean temperature in Stockholm over the last 200 years has been about 6.2 C.
standard deviations and variance¶
std(data[:,3]), var(data[:,3])
min and max¶
# lowest daily average temperature
data[:,3].min()
# highest daily average temperature
data[:,3].max()
sum, prod, and trace¶
d = arange(0, 10)
d
# sum up all elements
sum(d)
# product of all elements
prod(d+1)
# cummulative sum
cumsum(d)
# cummulative product
cumprod(d+1)
# same as: diag(A).sum()
trace(A)
Computations on subsets of arrays¶
We can compute with subsets of the data in an array using indexing, fancy indexing, and the other methods of extracting data from an array (described above).
For example, let's go back to the temperature dataset:
!head -n 3 stockholm_td_adj.dat
The dataformat is: year, month, day, daily average temperature, low, high, location.
If we are interested in the average temperature only in a particular month, say February, then we can create a index mask and use it to select only the data for that month using:
unique(data[:,1]) # the month column takes values from 1 to 12
mask_feb = data[:,1] == 2
# the temperature data is in column 3
mean(data[mask_feb,3])
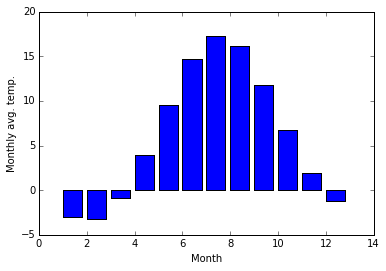
With these tools we have very powerful data processing capabilities at our disposal. For example, to extract the average monthly average temperatures for each month of the year only takes a few lines of code:
months = arange(1,13)
monthly_mean = [mean(data[data[:,1] == month, 3]) for month in months]
fig, ax = plt.subplots()
ax.bar(months, monthly_mean)
ax.set_xlabel("Month")
ax.set_ylabel("Monthly avg. temp.");
Calculations with higher-dimensional data¶
When functions such as min, max, etc. are applied to a multidimensional arrays, it is sometimes useful to apply the calculation to the entire array, and sometimes only on a row or column basis. Using the axis argument we can specify how these functions should behave:
m = random.rand(3,3)
m
# global max
m.max()
# max in each column
m.max(axis=0)
# max in each row
m.max(axis=1)
Many other functions and methods in the array and matrix classes accept the same (optional) axis keyword argument.
Reshaping, resizing and stacking arrays¶
The shape of an Numpy array can be modified without copying the underlaying data, which makes it a fast operation even for large arrays.
A
n, m = A.shape
B = A.reshape((1,n*m))
B
B[0,0:5] = 5 # modify the array
B
A # and the original variable is also changed. B is only a different view of the same data
We can also use the function flatten to make a higher-dimensional array into a vector. But this function create a copy of the data.
B = A.flatten()
B
B[0:5] = 10
B
A # now A has not changed, because B's data is a copy of A's, not refering to the same data
Adding a new dimension: newaxis¶
With newaxis, we can insert new dimensions in an array, for example converting a vector to a column or row matrix:
v = array([1,2,3])
shape(v)
# make a column matrix of the vector v
v[:, newaxis]
# column matrix
v[:,newaxis].shape
# row matrix
v[newaxis,:].shape
Stacking and repeating arrays¶
Using function repeat, tile, vstack, hstack, and concatenate we can create larger vectors and matrices from smaller ones:
tile and repeat¶
a = array([[1, 2], [3, 4]])
# repeat each element 3 times
repeat(a, 3)
# tile the matrix 3 times
tile(a, 3)
concatenate¶
b = array([[5, 6]])
concatenate((a, b), axis=0)
concatenate((a, b.T), axis=1)
hstack and vstack¶
vstack((a,b))
hstack((a,b.T))
Copy and "deep copy"¶
To achieve high performance, assignments in Python usually do not copy the underlaying objects. This is important for example when objects are passed between functions, to avoid an excessive amount of memory copying when it is not necessary (technical term: pass by reference).
A = array([[1, 2], [3, 4]])
A
# now B is referring to the same array data as A
B = A
# changing B affects A
B[0,0] = 10
B
A
If we want to avoid this behavior, so that when we get a new completely independent object B copied from A, then we need to do a so-called "deep copy" using the function copy:
B = copy(A)
# now, if we modify B, A is not affected
B[0,0] = -5
B
A
Iterating over array elements¶
Generally, we want to avoid iterating over the elements of arrays whenever we can (at all costs). The reason is that in a interpreted language like Python (or MATLAB), iterations are really slow compared to vectorized operations.
However, sometimes iterations are unavoidable. For such cases, the Python for loop is the most convenient way to iterate over an array:
v = array([1,2,3,4])
for element in v:
print(element)
M = array([[1,2], [3,4]])
for row in M:
print("row", row)
for element in row:
print(element)
When we need to iterate over each element of an array and modify its elements, it is convenient to use the enumerate function to obtain both the element and its index in the for loop:
for row_idx, row in enumerate(M):
print("row_idx", row_idx, "row", row)
for col_idx, element in enumerate(row):
print("col_idx", col_idx, "element", element)
# update the matrix M: square each element
M[row_idx, col_idx] = element ** 2
# each element in M is now squared
M
Vectorizing functions¶
As mentioned several times by now, to get good performance we should try to avoid looping over elements in our vectors and matrices, and instead use vectorized algorithms. The first step in converting a scalar algorithm to a vectorized algorithm is to make sure that the functions we write work with vector inputs.
def Theta(x):
"""
Scalar implemenation of the Heaviside step function.
"""
if x >= 0:
return 1
else:
return 0
Theta(array([-3,-2,-1,0,1,2,3]))
OK, that didn't work because we didn't write the Theta function so that it can handle a vector input...
To get a vectorized version of Theta we can use the Numpy function vectorize. In many cases it can automatically vectorize a function:
Theta_vec = vectorize(Theta)
Theta_vec(array([-3,-2,-1,0,1,2,3]))
We can also implement the function to accept a vector input from the beginning (requires more effort but might give better performance):
def Theta(x):
"""
Vector-aware implemenation of the Heaviside step function.
"""
return 1 * (x >= 0)
Theta(array([-3,-2,-1,0,1,2,3]))
# still works for scalars as well
Theta(-1.2), Theta(2.6)
Using arrays in conditions¶
When using arrays in conditions,for example if statements and other boolean expressions, one needs to use any or all, which requires that any or all elements in the array evalutes to True:
M
if (M > 5).any():
print("at least one element in M is larger than 5")
else:
print("no element in M is larger than 5")
if (M > 5).all():
print("all elements in M are larger than 5")
else:
print("all elements in M are not larger than 5")
Type casting¶
Since Numpy arrays are statically typed, the type of an array does not change once created. But we can explicitly cast an array of some type to another using the astype functions (see also the similar asarray function). This always create a new array of new type:
M.dtype
M2 = M.astype(float)
M2
M2.dtype
M3 = M.astype(bool)
M3
Further reading¶
- http://numpy.scipy.org
- http://scipy.org/Tentative_NumPy_Tutorial
- http://scipy.org/NumPy_for_Matlab_Users - A Numpy guide for MATLAB users.
Versions¶
%reload_ext version_information
%version_information numpy