This note is a high-fidelity Markdown migration of the Linear Regression chapter from the LaTeX source.
Parent map: index Prerequisites: probability-and-mathstats
Concept map
flowchart TD A[Simple Linear Regression] --> B[OLS Estimator] B --> C[Finite-sample Properties] C --> D[Gauss-Markov BLUE] C --> E[Prediction / Intervals] B --> F[Projection Geometry] F --> G[FWL / Partitioned Regression] C --> H[Robust SEs] H --> I[Hypothesis Testing] I --> J[Multiple Testing] B --> K[Quantile Regression] B --> L[Measurement Error] B --> M[Bootstrap / Delta Method] B --> N[GMM] N --> O[Empirical Likelihood] N --> P[M-estimation]
1. Simple Linear Regression
Assume
with
1.1 OLS in summation form
Population best linear predictor coefficients:
Sample analogues:
Residual variance estimate in simple regression:
Variance decomposition from the fitted line and residual :
1.2 Properties of least-squares estimators
Let . Conditionally on regressors:
where
Component formulas:
Heteroskedastic scalar-regression asymptotic expression:
With multiple regressors, a useful form is
where is from regressing regressor on the other regressors and an intercept. This denominator gives the variance-inflation interpretation.
1.3 Prediction
For new covariate value :
Prediction-mean variance:
Forecast error has
Estimated prediction variance:
1.4 Simple regression in matrix form
With ,
Using block inversion, one can recover the standard simple-regression closed forms and show
2. Classical Linear Model
2.1 Assumptions
A common stack of assumptions:
- Linearity: .
- Exogeneity (strict/conditional): .
- Spherical errors: .
- Full column rank: .
- Normal errors (for exact finite-sample normality): .
- I.I.D. sampling of when using random-design asymptotics.
Notes:
- Assumptions 1-4 give unbiasedness and Gauss-Markov efficiency statements.
- Replacing homoskedasticity with yields under normality.
2.2 Optimization derivation of OLS
OLS solves
FOC:
With fixed regressors and homoskedasticity:
3. Finite and Large Sample Properties of and
3.1 Finite-sample unbiasedness (conditional on )
Under linear model + exogeneity,
A common caveat in the source notes: if you try to manipulate unconditional expectations through random matrix inverses directly, naive ratio-of-expectations shortcuts fail.
3.2 Finite-sample variance
under homoskedasticity.
With normality:
3.3 Gauss-Markov (BLUE)
Within linear unbiased estimators, OLS has minimum variance: for any linear unbiased ,
in PSD ordering (equivalently is PSD).
3.4 Large-sample conditions and consistency
Typical conditions in the notes:
- finite positive-definite ,
- fourth moments of regressors and errors finite,
- positive-definite .
Consistency decomposition:
3.5 Asymptotic normality and sandwich variance
with
Sample robust (Huber-White) form:
In scalar simple regression this reduces to
3.6 Unbiasedness of
Using and ,
Hence is unbiased conditionally on .
3.7 Polynomial approximation and sieve intuition
Wierstrass theorem in this context supports approximating continuous conditional mean functions on compact support by high-order polynomials.
A polynomial sieve estimator of takes
where but for consistency.
4. Geometry of OLS
Define
Properties:
- symmetric,
- idempotent,
- PSD,
- ,
- .
Fitted and residual vectors:
4.1 Frisch-Waugh-Lovell theorem
Partition . Let . Then
So coefficients on equal regression of residualized on residualized after partialling out .
4.2 Partitioned regression equations
Normal equations under partitioning:
FWL gives the equivalent closed-form block solutions via and .
5. Relationships Between Exogeneity Assumptions
For :
- mostly normalizes intercept handling.
- Consistency for slope uses .
- Mean independence implies zero covariance.
- Zero covariance does not imply mean independence.
- Full independence is stronger than mean independence.
Common failures of :
- Omitted variable bias.
- Measurement error.
- Simultaneity / reverse causality.
6. Residuals and Diagnostics
6.1 Leverage
Because
diagonal measures influence of observation on its fitted value.
6.2 Residual variance by leverage
From ,
6.3 Standardized and studentized residuals
where omits observation .
6.4 Cook’s distance
Let omit observation and . Then
A common heuristic is signals influential points.
7. Other Least-Squares Estimators
7.1 Robust regression (Huber loss)
with Huber loss
This behaves like squared loss near zero and absolute loss in tails.
7.2 Weighted least squares (WLS)
7.3 Generalized least squares (GLS)
If known,
7.4 Restricted OLS
Under linear restrictions , solve via Lagrangian
8. Goodness of Fit and Model Selection
Define:
- Total sum of squares: ,
- Explained sum of squares: ,
- Residual sum of squares: .
Decomposition:
8.1 and adjusted
8.2 Information and subset criteria
Mallows (as written in source notes):
AIC:
BIC:
8.3 F-statistic and Wald statistic
Joint linear restrictions :
Equivalent model-comparison form:
Generic nonlinear Wald statistic:
with asymptotic reference.
8.4 Generalization error and LOOCV
Generalization error:
for a new draw .
Training error:
often .
Leave-one-out CV:
Using average leverage ,
For ridge with penalty , effective degrees of freedom:
where are eigenvalues of .
9. Multiple Testing Corrections
Testing many hypotheses with per-test size :
- Probability of no false rejection under independent true nulls: .
- Probability of at least one false rejection: .
9.1 FWER
Let true-null index set be and rejected set be .
Equivalent with number of type I errors:
Methods:
- Bonferroni: threshold for tests.
- Holm-Bonferroni stepdown: sequentially compare ordered -values to .
- Resampling methods (Romano-Wolf, Westfall-Young) when dependence matters.
9.2 Joint confidence bands
If
seek intervals
with joint coverage approaching .
The critical value is calibrated from the distribution of the sup-norm of a standardized Gaussian draw (often via simulation plugging in ).
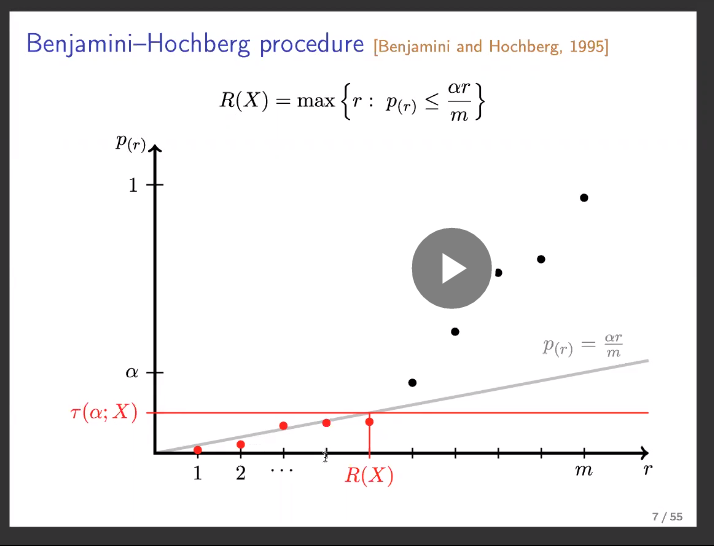
9.3 FDP / FDR and Benjamini-Hochberg
Setup:
- hypotheses ,
- -values (not necessarily independent),
- rejected set with ,
- false rejections .
Then
BH procedure at level :
- Sort .
- Reject up to
- Equivalent threshold rule:
Adjusted BH -value interpretation:
10. Quantile Regression
Based on Koenker-style setup.
10.1 Conditional quantile function
Define conditional CDF
Conditional quantile at level :
Linear quantile model:
10.2 Relation to heteroskedasticity
If
then with standard-normal quantile,
Thus quantile effects vary with when variance is covariate-dependent; under homoskedasticity, quantile slopes coincide across .
10.3 Quantile-regression estimator
Check-loss objective:
with
Equivalent split form:
Asymptotic distribution in source notation:
where
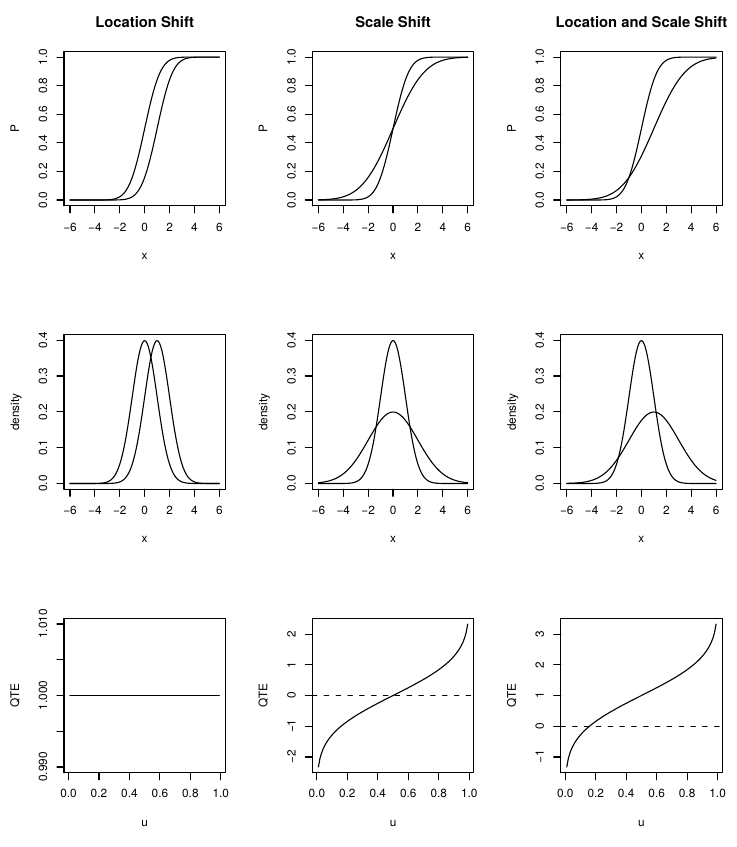
10.4 Lehmann-Doksum quantile treatment effect
Let be CDF of (control) and be CDF of (treated). Define horizontal shift via
Then
is the QTE.
ATE from QTE:
Empirical analogue:
Regression analogue:
10.5 Interpreting transformed quantile models
If monotone transform yields
then effects on follow via inverse-transform differentiation.
Example with log outcome: if modeling , marginal effects on scale by .
11. Measurement Error
11.1 Error in outcome variable
If observed and true model is , then observed regression is
OLS slope remains unbiased if is orthogonal to :
Variance inflates because noise increases error variance.
11.2 Error in regressor (classical EIV)
If true regressor observed with error and
then observed equation has composite error correlated with , so OLS is inconsistent.
Scalar attenuation result:
shrinking toward zero.
If measurement error ratio is , this reliability factor equals .
11.3 Correlated regressors and measurement error
With correlated regressors, attenuation in one regressor can propagate bias into others and often worsens distortion.
11.4 IV remedy
If instrument satisfies
then in bivariate case
12. Missing Data
Categories in source notes:
- MAR (missing at random): missingness may depend on other observables but not on the missing value itself, conditional on observables.
- MCAR (missing completely at random): observed sample is random subsample of full data.
- NMAR (not missing at random): neither MAR nor MCAR.
13. Inference on Functions of Parameters
13.1 Bootstrap
Core principle: resample from empirical CDF and recompute statistic to approximate its sampling distribution.
Algorithm:
- From data , draw bootstrap sample (with replacement).
- Compute statistic .
- Repeat times.
- Use empirical distribution of for SEs/quantiles/bias correction.
Bootstrap SE:
Bias logic:
13.2 Edgeworth expansion intuition
For standardized mean,
with remainder term under regularity conditions.
13.3 Jackknife
Define leave-one-out estimates
A standard jackknife variance estimate is
13.4 Asymptotically pivotal statistics
A statistic is asymptotically pivotal if its limit distribution does not depend on unknown nuisance parameters.
13.5 Cluster wild bootstrap (few clusters)
Source algorithm (CGM style):
- Estimate restricted model under null and get residuals .
- For each bootstrap draw, assign each cluster a Rademacher weight .
- Form pseudo-residuals and pseudo-outcomes
- Re-estimate unrestricted model on pseudo-data and compute test statistic .
- Bootstrap -value from tail proportion of relative to observed .
13.6 Delta method / propagation of error
If quantity of interest is
Taylor expansion gives variance propagation:
General vector form with :
Scalar standardized form:
with
13.7 Parametric bootstrap
Assume asymptotic parameter distribution is valid and simulate:
for , then summarize empirical distribution of .
14. Generalized Method of Moments (GMM)
14.1 Linear GMM setup
Data , with , , instruments , and .
Model:
If just-identified ():
Overidentified weighted criterion:
14.2 General moment-condition formulation
Given moments
with , , , define
GMM objective:
Jacobian:
Identification language:
- underidentified if rank,
- just identified if rank and ,
- overidentified if with full rank for identified directions.
Asymptotic normality:
where
14.3 Technical regularity conditions (summary)
The notes list standard requirements:
- compact parameter space,
- global identification,
- uniform LLN behavior of moments,
- continuity/differentiability of moment functions,
- finite moments,
- ,
- interior true parameter.
14.4 Two-step efficient GMM
Variance-minimizing asymptotic weight is , giving
Practical two-step algorithm:
- Initialize .
- Compute preliminary .
- Estimate at .
- Set .
- Re-optimize to get efficient .
14.5 Standard methods nested in GMM
- OLS moments: .
- IV/2SLS moments: .
- MLE moments: score equations .
15. Empirical Likelihood and Generalized Empirical Likelihood
15.1 Nonparametric likelihood
For IID with CDF , nonparametric likelihood:
ECDF maximizes this criterion:
15.2 NPMLE as constrained optimization
Assign discrete masses on observed points and solve
Solution is .
15.3 Empirical likelihood with moment restrictions
Given moments
solve
subject to
Lagrange multipliers induce implicit equations for :
plus corresponding score equation in .
Dual saddlepoint form:
15.4 Generalized empirical likelihood (GEL)
Replace log criterion with shape-constrained satisfying normalizations at 0:
Special cases in notes:
- gives EL,
- gives CUE,
- gives exponential tilting.
Primal formulation uses Cressie-Read divergence family for weights.
16. M-estimation
M-estimator solves
with i.i.d. observations and estimating function .
Asymptotic sandwich variance:
where
This framework nests many estimators. For MLE, is the score.