This note is a high-fidelity Markdown migration of the Probability and Mathematical Statistics chapter from the LaTeX source.
Parent map: index
Concept map
flowchart TD A[Probability Space] --> B[Random Variable] B --> C[CDF] C --> D[PDF/PMF] C --> E[Quantile Function] D --> F[Expectation] F --> G[Variance/Covariance] D --> H[MGF / CGF / Characteristic Function] F --> I[LLN] G --> J[CLT] J --> K[Asymptotic Inference]
1. Basic Concepts and Distribution Theory
Probability
Given a measurable space , if , then is a probability measure and is a probability space.
- sets are events,
- points are outcomes,
- is the probability of event .
Kolmogorov axioms
A triple is a probability space if:
- Unitarity: .
- Non-negativity: for all .
- Countable additivity: for pairwise disjoint ,
Immediate consequences:
- ,
- ,
- ,
- .
Basic probability facts
For events :
- ,
- ,
- ,
- .
Random variable
A random variable is a measurable map such that
Continuous random variable (pushforward view)
If sample space is and event space is , define
DeMorgan, inclusion-exclusion, conditional probability
- DeMorgan: and .
- Inclusion-exclusion:
- Conditional probability:
Bayes rule
Density form:
Statistical independence
2. Densities and Distributions
Distribution function (CDF)
A CDF is defined by
Also define , so
Properties of CDFs:
- Bounded: , .
- Nondecreasing: .
- Right-continuous: .
- Left-limit relation:
If exists and
then is absolutely continuous with density .
Empirical CDF for :
Density / PMF
For continuous case,
so where derivative exists.
For discrete case, analogously use mass .
Density properties:
- ,
- .
Integration with respect to distribution function
For any measurable set ,
(Lebesgue-Stieltjes form).
If absolutely continuous:
and for measurable ,
Quantile function / inverse CDF
For ,
Check loss:
For continuous , minimizes expected check loss at quantile level .
Properties of quantile functions
- ,
- ,
- ,
- if strict inverse exists, ,
- .
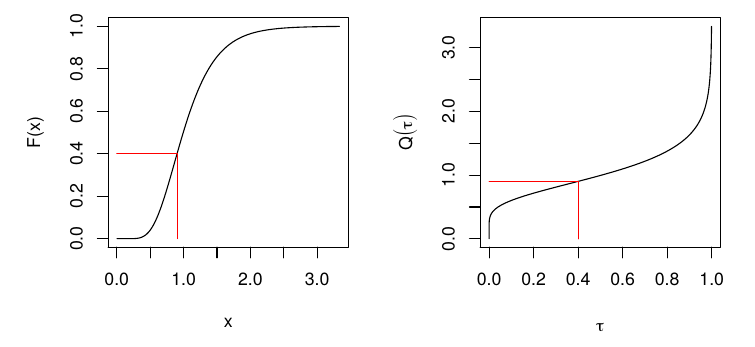
Equivariance of quantiles under monotone transformations
If is nondecreasing and is a random variable,
Lorenz curve and Gini coefficient
For positive with mean and quantile function ,
Gini mean difference:
2.1 Multivariate Distributions
Random vectors
A -vector random variable is with components .
Joint CDF:
If continuous,
Marginals and conditionals
For coordinate :
Conditional density for :
For bivariate :
Independence (distributional statements)
and are independent if
Useful implications under independence:
- ,
- ,
- .
3. Moments
For random variable with support :
- th raw moment: ,
- th central moment: .
Expectation and variance
Expectation is the Lebesgue-Stieltjes integral of with respect to .
Equivalent notation includes and .
Variance-covariance matrix
For vectors:
Skewness and kurtosis
Linear transformations
For matrix and vector random variable with covariance :
If :
Also,
in the standard multivariate normal setup with matching dimension.
Law of the unconscious statistician (LOTUS)
If ,
Linear combinations and covariance algebra
For vectors,
Moment generating function (MGF) and Laplace transform
For nonnegative , Laplace transform:
MGF:
If MGF exists around ,
so
Cumulant generating function (CGF)
with expansion
where cumulants are
Characteristic function
If MGF exists, . Characteristic functions always exist.
Order statistics
If are i.i.d. with CDF and PDF , then density of th order statistic is
Correlation coefficient
- iff with ,
- iff with .
Entropy, KL divergence, and mutual information
For discrete random variable with PMF ,
Properties include:
- ,
- change of base relation,
- conditioning reduces entropy: ,
- with equality for uniform,
- is concave in .
Relative entropy (KL divergence):
Mutual information:
Equivalent forms:
Copulas and Fréchet bounds
For random variables with marginals and joint CDF ,
Fréchet bounds:
Special cases:
- upper bound: comonotonic dependence,
- lower bound: countermonotonic dependence,
- independence: .
4. Transformations of Random Variables
4.1 Useful inequalities
The central question is to bound tail probabilities such as
Cauchy-Schwarz
For random variables with finite second moments,
Hence
Jensen
If is concave and expectations exist,
If is convex,
Markov
For nonnegative and ,
Special case:
Chebyshev
If and ,
Kolmogorov inequality (as stated in source notes)
For independent mean-zero variables with finite second moments,
Chernoff-type bound identity
For any random variable and ,
Hölder
For with ,
Hoeffding lemma form
If , then for all ,
5. Transformations and Conditional Distributions
Let .
CDF method for transformations
for monotone invertible .
Change of variables for density
Scalar case:
Multivariate case:
Example: when
If ,
so
Conditional expectation
For jointly continuous ,
For function ,
Conditional variance
Law of iterated expectations
Law of total variance
5.1 Distribution facts and links
Normal facts
If and :
- ,
- if , then .
Multivariate normal
For ,
Linear image:
Common links
- Student- from normal over square-root chi-square ratio,
- from ratio of scaled chi-square variables,
- Bernoulli as Binomial,
- Uniform as Beta,
- Exponential as Gamma,
- as Gamma,
- Geometric as NegBin.
Misc facts
- Exponential is memoryless:
- Poisson inter-arrival times are exponential.
- If , then is wait time to arrivals in a Poisson process of rate .
Exchangeability
are exchangeable if any permutation has the same joint distribution.
Martingales
A sequence with is a martingale if
6. Statistical Decision Theory
A statistical decision problem is a game between nature and a decision maker.
- Nature chooses and generates data from .
- DM observes data and chooses action .
- Utility/loss depends on .
Statistical problem tuple
A decision rule is .
Example: estimation
- action space ,
- decision rule is estimator,
- common loss: quadratic loss .
Example: testing
Partition into null and alternative .
- action space ,
- decision rule is test,
- common loss: zero-one misclassification loss.
Example: interval inference
Actions are confidence sets .
Risk and admissibility
Risk of :
is dominated by if for all . Undominated rules are admissible.
James-Stein shrinkage example
If , estimate vector under squared loss
MLE is , but for , shrinkage estimator
has lower risk than the coordinatewise MLE.
Bayes risk and Bayes rule
Given prior on :
A Bayes rule minimizes over admissible .
Minimax
is minimax if
7. Estimation
Sample statistic
For i.i.d. , a sample statistic is
Unbiasedness
is unbiased if
Consistency
is consistent if
Asymptotic normality
Sampling variance
For estimator , sampling variance is .
Mean squared error (MSE)
Also,
Mean and variance estimators
- is unbiased for ,
- is unbiased for .
If :
- ,
- ,
- and are independent,
8. Hypothesis Testing
Test statistic and test
A test statistic is a sample function . A test is a map from statistic space to (reject / do not reject).
Standard normal-style statistic:
with rejection in two-sided test when .
Null and alternative
- is maintained unless contradicted,
- is alternative.
Decision rule partitions statistic support into acceptance and rejection regions.
Type I/II, power
| Decision | Null true | Null false |
|---|---|---|
| Reject | Type I error | Power |
| Do not reject | Type II error |
Power function:
Size of test:
Two-sided normal-approximation confidence interval
P-values
- two-sided: ,
- one-sided: or depending on alternative direction.
9. Convergence Concepts
Asymptotics studies how estimators behave as , often targeting asymptotic normality of scaled errors.
Modes of convergence
For sequence :
- in probability: ,
- in mean square: if ,
- in distribution: .
Standard implications:
- ,
- ,
- ,
- if limit is constant , .
9.1 Laws of Large Numbers
Basic statement:
Chebyshev LLN
If i.i.d. with finite mean and variance,
Strong LLN
Under standard finite-variance conditions,
Glivenko-Cantelli
For i.i.d. sample from CDF ,
obeys
This gives consistency of the empirical CDF and empirical quantiles.
9.2 Central Limit Theorem
For i.i.d. with mean and variance ,
or equivalently
9.3 Tools for transformations
Continuous mapping theorem
- If and continuous, then .
- If and continuous, then .
Slutsky
If and ,
- ,
- ,
- if .
Delta method
If
and is continuously differentiable at , then
Scalar form:
9.4 Orders of magnitude
For deterministic functions as argument approaches :
- if bounded,
- if ,
- if .
Constant order means .
9.5 Stochastic orders
For sequences:
- means is stochastically bounded,
- means .
Common identities:
- ,
- ,
- ,
- .
Example consistency decomposition:
10. Parametric Models
Parametric model
For outcome and covariates , a parametric model is
with finite-dimensional parameter .
Model is true if there exists such that
Identifiability means distinct parameters imply distinct distributions:
Regression model view
Independent (not necessarily identically distributed) with parameter , and known covariates satisfy
is known; is unknown.
Classical linear model example
with parameter space
Binary choice example
For ,
with known link (logit/probit).
Fisher-Neyman factorization theorem
Statistic is sufficient for iff
Equivalent Bayesian statement: posterior depends on only through .
11. Robustness
Write estimators as functionals of empirical CDF:
Examples:
- mean: ,
- median: ,
- trimmed mean:
Let denote distribution of estimator under data law .
Prokhorov distance
For probability measures on metric space,
Hampel robustness
Estimator sequence is robust at if
Influence function
For contamination model ,
Examples from notes:
- mean: ,
- variance: .
Both are unbounded as , highlighting non-robustness to outliers.
12. Identification
A data-generating process (DGP) fully specifies the stochastic process generating observables.
A model is a family of admissible DGPs and can be:
- parametric,
- nonparametric,
- semiparametric.
Semiparametric OLS example
with finite-dimensional and otherwise unrestricted joint law.
Index-model semiparametric example
where and error distribution are nuisance objects.
Generic nonparametric model
with unrestricted marginals and target functionals such as .
Structural representation
Many models can be represented as
with structure
Identified set
If is observed distribution and is implied by structure , then
- point identified: is singleton,
- partial identification: has multiple elements.
Observational equivalence
and are observationally equivalent if
Ceteris paribus effect in structural model
For ,
If and structure is identified, distribution of causal effects can be identified.
Statistical functionals and estimands
If model-indexed laws are
then a functional is a map
In causal inference, such functionals are estimands.